Neural Networks
Artificial Intelligence
| Developed by Hardeep Singh | |
| Copyright | © Hardeep Singh, 2001 |
| [email protected] | |
| Website | SeeingWithC.org |
| All rights reserved. | |
| The code may not be used commercially without permission. | |
| The code does not come with any warranties, explicit or implied. | |
| The code cannot be distributed without this header. | |
Problem: In all other
discussions on this site, I first discuss a practical problem and
then suggest alternative solutions to it. However, in this write-up,
I diverge from the trend. Here, I first suggest an Artificial Intelligence
technique, which is modeled on the way humans learn to do things, and then
suggest uses for it.
We will try to make a program automatically learn
a boolean function, the way our brain learns things.
Solution:
Take for example, the task of learning how to play the piano. When we
try to for the first time, we fare badly. However, we stick to and
each hour of practice we put in, takes us closer to our goal, until we
can play it well.
Scientists trying to understand the working of human brain think our brain
has networks of Neurons (nerve cells). Each neuron can conduct (the signal) or not
conduct depending on the input, its weights and a threshold value.
In scientific terms, neurons fire or not depending on the summed strength of their
inputs across synapses of various strengths.
Initially, the neural network (in our brain) has random weights and thus does not do the
given task well. As we practice, the brain keeps adjusting the weights and the
threshold values of neurons in the network. After a while, when the weights are
adjusted, we call the neural network, trained and we can do the task well.
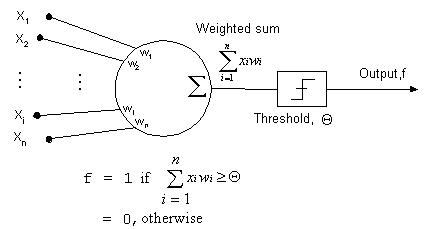
We model a neuron through a simpler representation called a Threshold Logic Unit (TLU). A schematic diagram of a TLU is shown below:
As can be seen from the diagram, a TLU has various inputs X1,X2,...,Xn. These inputs are multiplied with the corresponding weights and added together. If this sum is greater than the threshold value, the output is a high(1). Otherwise, the result is low(0).
Here is a TLU implementing a boolean function:
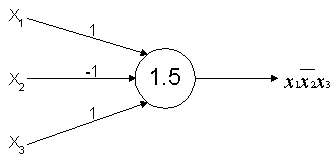
If the inputs to this TLU are
X1 = 1, X2 = 1 and X3 = 1.
The sum of weighted inputs is, X1W1 + X2W2 + X3W3
= 1(1)+1(-1)+1(1) = 1. Since this is less than the threshold value of 1.5,
the output is a 0, as expected.
However, if the inputs to this TLU are
X1 = 1, X2 = 0 and X3 = 1.
The sum of weighted inputs is, 1(1)+1(0)+1(1)=2. This is greater than the
threshold value of 1.5, and now the output is 1.
Although a single TLU is sufficient to implement simple boolean functions (functions that are monomials or disjunction of literals), not all functions can be implemented in this way. Examples are the XOR and the even parity function. For such functions, a network of TLUs is needed. Such a network of TLUs is called a Neural Network. A neural net implementation for the even parity function is given below:
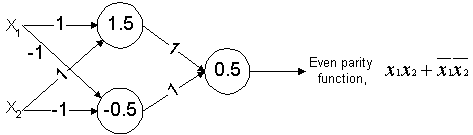
The intermediate TLUs (those with thresholds 1.5 and -0.5) are said to constitute the hidden layer. TLUs with one hidden layer can learn any boolean function (although the actual number of TLUs in this layer may need to be increased with increase in number of variables). For more specialised tasks, neural nets may have more hidden layers. However, we will not concern ourselves with such nets here, although the general procedure for training them is the same.
To start with, the weights in the TLU and the threshold value are randomly
decided. Then, the TLU is presented the expected output for a particular input.
For the given input, the output of the TLU is also noted. Usually, because
the weights are random, the TLU responds in error. This error is used to
adjust weights so that the TLU produces the required output for the given input.
Similarly, all the expected values in the training set are used to adjust the
weights.
Once the TLU is trained, it will respond correctly for all inputs in
the training set. Also, now that the TLU is trained, we can use it to calculate
the output for inputs not in the training set.
Now the next question that arises is, How do we adjust the TLU weights for the
sample input?
Although many methods exist for this purpose, we will be using the
Generalized Delta Procedure. Under this procedure, the threshold function
is temporarily (for the purpose of training) replaced by a sigmoid
(S shaped) function. The function we use is
 .
.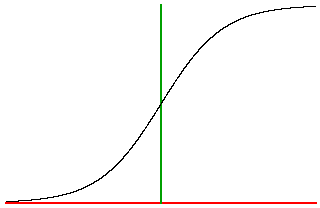
As can be seen, this is not much different from the threshold function. This
function has the benefit of being differentiable. This property is used to
find the weight change rule, as given below. After the result from the TLU
does not match the desired result from the training set, the weights are adjusted
according to the formula:
Since the threshold function also needs to be adjusted during training, we use the concept of Augmented Vectors. For this, we add a new input to the TLU, Xn+1 and a new weight for this input, Wn+1. The input Xn+1 remains at 1 and the weight Wn+1 is adjusted as usual. The threshold value is fixed at 0. After the training, we discard the additional input and set threshold = the new, adjusted value of Wn+1. Convince yourself that the new, augmented TLU gives the same result as the other.
/* Program to train a 2 layer feedforward neural network to learn any boolean
function */
/* Copyright: Hardeep Singh, 2001.
All rights reserved.
Email: [email protected]
*/
/*
An example: (with 4 variables)
function=x'y'z'+x'yz+xy'z+xyz
Enter Training Sample: 000 1, 010 0, 011 1, 100 0, 110 1
Returns correct values for the rest: 001, 101, 111
*/
#include <math.h>
#include <conio.h>
#include <process.h>
#include <stdlib.h>
#include "myown.h"
//contains some simple I/O functions. you can write them yourself
#define MAXNVAR 25
//maximum number of allowed variables; should be TLU_MULTIPLIER*Actual maximum
#define TLU_MULTIPLIER 1
//defines the number of hidden layer TLUs per variable. actually should be
//2^nVar but less will do. can be increased to 100
//this later appears to be redundant, 1 is sufficient
#define MAXINPUT 100
//maximum number of training samples input
#define MAXLOOP 30000
//maximum number of times a NNet can be trained on a given input
#define C 1
//constant of learning. 1 is ok. better if 0.1 or 0.01 (my ideas)
#define EPSILON 0.000001
void checkAlloc(void *v)
{
if (!v) {
printf("Unable to initialise Neural Net: Memory problem.");
exit(1);
}
}
class TLU {
private:
double weights[MAXNVAR];
int nVar; //number of variables
double thresh; //threshold value: ALWAYS 0
public:
TLU();
void setWeight(int i,double value); //i starts at 0
double getWeight(int i);
double getThresh();
double evSigmoid(double x[MAXNVAR]); //evaluates using sigmoid function
int evThresh(double x[MAXNVAR]); //evaluates using threshold function
void setnVar(int i);
int getnVar();
int doTrain(int x[MAXNVAR],double d) {return 0;}
//stubbed because not required
//in current problem
//returns a boolean saying if any weight was changed during training
};
TLU::TLU()
{
thresh=nVar=0;
for (int i=0;i<MAXNVAR;i++)
weights[i]=0;
}
void TLU::setWeight(int i,double value)
{
weights[i]=value;
}
double TLU::getWeight(int i)
{
return weights[i];
}
double TLU::getThresh()
{
return thresh;
}
double TLU::evSigmoid(double x[MAXNVAR])
{
double sum=0.0;
for (int i=0;i<nVar;i++)
sum+=x[i]*weights[i];
return 1/(1+exp(-sum));
}
int TLU::evThresh(double x[MAXNVAR])
{
double sum=0.0;
for (int i=0;i<nVar;i++)
sum+=x[i]*weights[i];
return sum>thresh?1:0;
}
void TLU::setnVar(int i)
{
nVar=i;
}
int TLU::getnVar()
{
return nVar;
}
class NNet { //neural net specific to the problem
private:
TLU *hidden;
TLU final; //this TLU has TLU_MULTIPLIER*nVar+1 variables,
//one is for threshold function (augmentation)
int nVar;
double doTrainEv(double x[MAXNVAR]);
public:
NNet(int nVar); //no default constructor
~NNet();
int doTrain(double x[MAXNVAR],double d);
int doEvaluate(double x[MAXNVAR]);
TLU getHiddenTLU(int i);
TLU getFinalTLU();
};
NNet::NNet(int nVar)
{
this->nVar=nVar;
hidden=new TLU[TLU_MULTIPLIER*nVar];
checkAlloc(hidden);
for (int i=0;i<TLU_MULTIPLIER*nVar;i++)
hidden[i].setnVar(nVar);
final.setnVar(nVar*TLU_MULTIPLIER+1);
//randomize weights; this is important - without this, convergence is very slow
randomize();
for (i=0;i<TLU_MULTIPLIER*nVar;i++)
for (int j=0;j<nVar;j++) {
hidden[i].setWeight(j,random(11)-5);
}
for (j=0;j<final.getnVar();j++) {
final.setWeight(j,random(11)-5);
}
}
NNet::~NNet()
{
delete hidden;
}
//returns a boolean saying if any weight was changed during training
int NNet::doTrain(double x[MAXNVAR],double d)
{
double f=doEvaluate(x);
int ret=false;
if (fabs(f-d)>EPSILON) {
f=doTrainEv(x);
ret=true;
double *fhid=new double[TLU_MULTIPLIER*nVar];
checkAlloc(fhid);
for (int i=0;i<TLU_MULTIPLIER*nVar;i++)
fhid[i]=hidden[i].evSigmoid(x);
double delta=(d-f)*f*(1-f);
double *dhid=new double[TLU_MULTIPLIER*nVar];
checkAlloc(dhid);
for (i=0;i<TLU_MULTIPLIER*nVar;i++)
dhid[i]=fhid[i]*(1-fhid[i])*delta*final.getWeight(i);
for (i=0;i<final.getnVar();i++)
final.setWeight(i,final.getWeight(i)+C*delta*(i<final.getnVar()-1?fhid[i]:1));
//this conditional opertor handles the case of final input that always
//remains high. augmented vectors again
for (i=0;i<TLU_MULTIPLIER*nVar;i++)
for (int j=0;j<nVar;j++)
hidden[i].setWeight(j,hidden[i].getWeight(j)+C*dhid[i]*x[j]);
if (fhid)
delete fhid;
if (dhid)
delete dhid;
}
return ret;
}
int NNet::doEvaluate(double x[MAXNVAR])
{
double *inter=new double[TLU_MULTIPLIER*nVar+1];
for (int i=0;i<TLU_MULTIPLIER*nVar;i++)
inter[i]=hidden[i].evThresh(x);
inter[i]=1;
int ret=final.evThresh(inter);
if (inter)
delete inter;
return ret;
}
double NNet::doTrainEv(double x[MAXNVAR])
{
double *inter=new double[TLU_MULTIPLIER*nVar+1];
for (int i=0;i<TLU_MULTIPLIER*nVar;i++)
inter[i]=hidden[i].evSigmoid(x);
inter[i]=1;
double ret=final.evSigmoid(inter);
if (inter)
delete inter;
return ret;
}
TLU NNet::getHiddenTLU(int i)
{
return hidden[i];
}
TLU NNet::getFinalTLU()
{
return final;
}
void main()
{
newpage; //clears the screen; same as clrscr();
printf("To end input anywhere, just press enter.\n");
int nVar=readint("Enter the number of variables ",1,MAXNVAR,1,1);
//reads a number between 1 and MAXNVAR
nVar++; //to hold augmented vector
//to the threshold function while printing
NNet net(nVar);
int input[MAXINPUT][MAXNVAR],dall[MAXINPUT],count=0; //d_all
do { //could someone improve the input loop, please?
char str[255];
double x[MAXNVAR],d;
printf("\nEnter the input x1x2...xn d >");
readstr(str,254);
if (str[0]==0)
break;
for (int i=0;i<nVar-1;i++)
x[i]=str[i]=='1'?1.0:0.0;
x[i]=1.0;//additional input
i++;
d=str[i]=='1'?1.0:0.0;
for (i=0;i<nVar;i++)
input[count][i]=x[i];
dall[count]=d;
count++;
} while(count<MAXINPUT);
int change=1;
for (int i=0;i<MAXLOOP && change;i++) {
change=0;
for (int j=0;j<count;j++) {
double x[MAXNVAR];
for (int m=0;m<nVar;m++)
x[m]=input[j][m];
change=net.doTrain(x,dall[j]) || change;
}
}
if (change)
printf("\nNeural net did not converge.");
else
printf("\nNeural net converged after %d iterations.",i+1);
printf("\nWant to see net(Y/N)?");
char ch=getchar();
clear; //flushes the input stream.
if (ch=='y' || ch=='Y') {
clear;
newpage;
for (int i=0;i<TLU_MULTIPLIER*nVar;i++) {
printf("Hidden TLU #%d:",i+1);
printf("\n\n");
printf("Weights:\n\n");
TLU t=net.getHiddenTLU(i);
for (int j=0;j<nVar-1;j++) {
printf("%lg",t.getWeight(j));
if (j!=nVar-2)
printf(",");
}
printf("\n\nThreshold=%lg",-t.getWeight(nVar-1));
//t.getThresh() is redundant; it will
//always return 0.0
(void) getche();
clear;
newpage;
}
printf("Final TLU:");
printf("\n\n");
printf("Weights:\n\n");
TLU t=net.getFinalTLU();
for (int j=0;j<t.getnVar()-1;j++) {
printf("%lg",t.getWeight(j));
if (j!=t.getnVar()-2)
printf(",");
}
printf("\n\nThreshold=%lg",-t.getWeight(t.getnVar()-1));
(void) getche();
clear;
newpage;
}
printf("\nWant to run net(Y/N)?");
ch=getchar();
clear;
if (ch!='y' && ch!='Y')
exit(0);
do {
char str[255];
double x[MAXNVAR],d;
printf("\nEnter the input x1x2...xn >");
readstr(str,254);
if (str[0]==0)
break;
for (int i=0;i<nVar-1;i++)
x[i]=str[i]=='1'?1.0:0.0;
x[i]=1.0;
d=net.doEvaluate(x);
printf("The result is %d\n",(int)d);
} while(1);
}
The program is self explanatory and instructive. It uses the concept of
Backpropagation, which can be understood by reading the program.
First, we have the generic TLU class that stores the weights. It has simple
implementations of functions such as that to evaluate a TLU based on the
sigmoid and the threshold function, and for getting and setting the various
properties. The function for training the TLU is stubbed because we train a
net rather than individual TLUs.
Then, we have the NNet class that implements a simplified Neural Network.
It does not implement a generic net, since it has provisions only
for one hidden layer, which is sufficient for our problem. It has the various
TLUs required and functions for training, evaluation etc. The doTrainEv()
function is private and can be called only while training. To evalutate the NNet,
doEvaluate() function can be called.
![]()